Deshalb ist diese Datenreihe vielleicht besser geeignet, stabile Rₜ-Werte zu schätzen.
Ich will das ab heute ausprobieren, gleichzeitig will ich das Modell 10 Tage früher starten lasse, also am 20. Februar. Dazu habe ich den Startwert für die Infizierten bei t=0 auf 790 gesetzt, er war vorher bei 1500. Das geschah durch Probieren verschiedener Werte und Auswahl nach der besten Anpassung an die Daten vom 20. Feb. bis 20. März.
Es bleibt bei dem Verfahren, jeweils 3 Rₜ für drei benachbarte Intervalle von dem automatischen Optimierung bestimmen lassen, den linken der drei Werte festschreiben, das Zeitfenster um 10 Tage nach rechts verschieben usw.
Den Unterschied zwischen dem alten und dem neuen Verfahren demonstriert die Abbildung
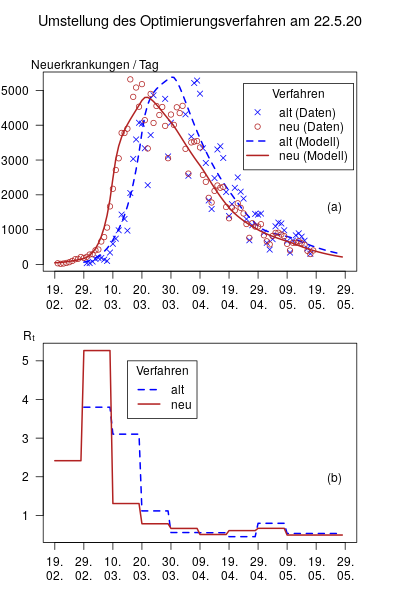
Man sieht in (a), dass die Beobachtungen sich systematisch unterscheiden. Der Erkrankungstermin liegt im Schnitt 5 Tage vor dem Meldetermin. Zusätzlich hat die Kurve eine erkennbar andere Form. Entsprechend unterscheiden sich die optimierten Rₜ-Werte (b). Der hohe Wert von ca. 5 im 2. Intervall liegt an einem früheren und steileren Anstieg in den Daten. Im april und Mai unterscheiden sich die beiden Verfahren nicht wesentlich.
Ich werde in diesem Blog bis auf weiteres die Ergebnisse des neuen Verfahrens präsentieren.
... link (2 Kommentare) ... comment
Aller Anfang
Es hat mich gestört, dass ich für den Anfang der Modellierung ein Intervall von 20 Tagen benutzt habe. Außerdem wollte ich noch einmal, den Einfluss des I₀, der für den 1. März angenommenen Infizierten, untersuchen.Ich teile jetzt also einheitlich die Zeit in 10-Tage-Intervalle ab 1.3.2020. Für diese Intervalle möchte ich R₀ bestimmen. Ich werde diese als R(1), R(2), ... für die Intervalle 1, 2, ... . Intervall 1 beginnt am 1.3.20. R(i) ist konstant im Intervall i (Treppenfunktion).
Ich konnte I₀ und R(1) nicht unabhängig bestimmen. Man kann zur Anpassung an die Daten sowohl das eine wie das andere erhöhen. Ich hatte eine gute Anpassung für I₀ = 1500 und setze das jetzt so fest. Den damit einhergehenden R(1)>6 sehe ich als Artefakt. Es ist anscheinend unmöglich, aus dem Anfang der Datenreihe die Startbedingungen zu identifizieren.
Die Raupe
Die R(i) werden gefunden, indem ein Programm sich tageweise vorarbeitet. Zu jedem Datum wird der zugehörige File (Datenstand) gelesen und es wird eine automatische Optimierung für die letzten drei R(i) vorgenommen. Die älteren R(i) werden festgeschrieben. Genauer, wenn bisher R(1) ... R(k) bestimmt wurden und wenn in Intervall R(k+1) mindestens 8 Werte vorliegen, wird es abgetrennt. R(k-1), R(k) und R(k+1) sind jetzt zufinden während R(k-2) festgestellt wird.Bewertung
R(1) ist nicht zu gebrauchen. R(2)≈4 hat sich immer wieder ergeben und scheint mir sicher. Mitte März gab es einen steilen Anstieg der Fallzahlen. R₀=4 ist für Deutschland (ohne Gegenmaßnahmen) möglich.Am Ende der Datenreihen dauert es 3 Wochen, bis der neueste R(i) von Bedeutung ist.
... link (0 Kommentare) ... comment